Some of my rough notes as I discover how I might go about doing some image processing in J.
This article mostly assumes you’ve been following my Learning J series: Part I, Part II, Part III, and Part IV.
Change working directory (cd) with «1!:44 ‘/Users/drj/project/fingerprint’». «!:» is the foreign conjunction.
Read file (as string): «t =. 1!:1 < ‘finger.pgm’» or a subset with «1!:11 ‘finger.pgm’;0 20».
The PGM file format is grayscale image format. It’s elegant simplicitly makes it ideal for prototyping image algorithms. It consists of a text header describing the width, height, and maxval (the value that represents maximum brightness, very commonly 255) followed by a big string of bytes (no compression, just the data in row major order).
Our first goal is to use J’s file mapping facilities which allow us to treat an array of bytes stored in a file as an array. For that we’ll need to find out the width, height, and maxval of the PGM file.
Regular expressions
require 'regex'
'(\S*\s+){3}(\S*\s)' rxmatch t
substrings can be extracted using the match results:
('P5\s+(\d*)\s+(\d*)\s+(\d*)\s' rxmatch t) rxfrom t
+-----------------+----+----+---+
|P5 3301 3397 255 |3301|3397|255|
+-----------------+----+----+---+
Observe that this duplicates t. That makes it candidate for a fork. Observe that the above expression has the form: «(x f y) g y». Recall that a fork «x (f g h) y» is the same as «(x f y) g (x h y)», so we can use a fork «’P5\s+(\d*)\s+(\d*)\s+(\d*)\s’ (rxmatch rxfrom h) t» if we can find a suitable h. We need a dyadic h such that «x h y» is y. Happily, «]» is such an h:
'P5\s+(\d*)\s+(\d*)\s+(\d*)\s' (rxmatch rxfrom ]) t
We can use «}.» to drop the first match (which describes the entire match, which I’m not really interested in):
'P5\s+(\d*)\s+(\d*)\s+(\d*)\s' (([: }. rxmatch) rxfrom ]) t
Notice the use of the cut «[:» and the extra set of parens.
Really we want to make a new monadic verb to extract the width, height, and maxval from a pgm file:
pgmxym =: ???
So we should bind the header regular expression onto rxmatch using the currying conjunction «&»:
pgmheader =: 'P5\s+(\d*)\s+(\d*)\s+(\d*)\s' pgmxym =: ([: }. pgmheader & rxmatch) rxfrom ]
By placing the inner trident on the right we can eliminate a set of parens. We can do that by using the «~» (twiddles – has a terrible rendering on my browser/CSS) adverb (called passive in J) to swap the operands to rxfrom:
pgmxym =: ] rxfrom~ [: }. pgmheader&rxmatch
and now it’s this way round we can drop the initial «]» to give us a bident on the left. Observe that the monadic trident «[ g h» is the same as the monadic bident «g h». Note that if we wanted a bident anywhere else we’d have to use parentheses. So we now have:
pgmxym =: rxfrom~ [: }. pgmheader&rxmatch
I’m starting to feel like a proper J coder now.
Now we need to convert a boxed list of strings into 3 numbers.
«x “. y» converts y to a number, defaulting to x when that’s not possible. But before I discovered that I went on a merry excursion to implement equivalent functionality myself. Since the excursion does include some useful learning things about J it turned out not to be completely pointless, but is now relegated to an appendix.
In my excursion I did learn that «|.» is reverse, and dyadic «x i. y» is the index of y within x. And I rely on one of those facts shortly.
atoi =: 0&". NB. much better than my version.
Mapped Files
require 'jmf' NB. J Mapped Files presumably (JCHAR;width;headersize) map_jmf_ 'arrayname';datafn
I need to supply width, which is the width in bytes of each row, and headersize which is the initial amount of file to skip before the array proper begins. Now I need all the results from rxmatch; I need the total length of the header (which is essentially the first item of the rxmatch results) and I need the strings for the remaining 3 matches to be converted into numbers. I think that’s currently beyond my powers to do in a tacit definition. Explicit it is then:
pgmlxym =: verb define
m =. pgmheader&rxmatch y NB. get matches
l =. 1{0{m NB. Length of header
l , atoi @ > }. m rxfrom t
)
'l w h m' =: pgmlxym t NB. sets 4 variables
(JCHAR;w;l) map_jmf_ 'fingerc';<'finger.pgm'
Cool. Now I have my image file as the array fingerc in J. There are two problems. The first is that it is an array of characters, not numbers; the second is that it’s huge and easy to accidentally print out as a J value (and being essentially binary data not edifying to print anyway). The first problem I can fix with: «finger =: a. i. fingerc» («a.» is alphabet, the list of characters in numerical order).
Simple operations can be performed. White–Black inversion: «f =. 255 – finger».
Now I have to figure out how to write a file out:
fd =. 1!:21 'foo' NB. open file called foo.
nf =. 0&": NB. convert number to string in Natural Format.
nf 127
127
nf h
3397
$nf h
4
('P5 ', (nf w), ' ', (nf h), ' 255 ') 1!:2 fd NB. , forms list.
g=. f { a. NB. convert from character to number array.
g 1!:3"0 1 0 fd NB. append each row to file.
1!:22 fd NB. close file.
We can use some J’s provided facilities to produce simple plots of brightness.
load'misc' nubcount ,/ finger
nubcount returns an N by 2 array where each item is entry, count. Where entry is one of the items of the operand to nubcount and count is the number of times it appeared. The list of unique items in a list is called its nub. The result array is an array of boxes because the counts are always numbers but the entries could be any type.
Do a nubcount and gather the nub into x and the corresponding counts into y:
x =. > 0{"1 count [ v =. > 1{"1 count [ count =. nubcount ,/ finger
Note the use of dyadic «[» which is really just being used to sequence 3 things on one line. The sequencing, of course, runs from right-to-left and this is a source of slight annoyance for me. I can sequence two things on seperate lines but when I want to put them on one line I can’t simply join the lines together with a «[» in between them. I have to swap the two lines round first.
It turns out that x does not have all the numbers from 0 to 255 (in other words its nub is not the same as «i. 256». This is because some values don’t appear in the input picture.
x i. i. 256
gives us a list in order from 0 to 255 of where that entry appears in x or «#x» when it doesn’t appear. We can now get counts for all values from 0 to 255, by using this list to index v. Extending v with a single 0 means we correctly get a 0 count for values that don’t appear:
(x i. i. 256) { v,0
and we can display this using plot:
plot (x i. i. 256) { v,0 NB. requires «require'plot'»
pd 'save bmp' NB. saves to file ~/j601/temp/plot.bmp
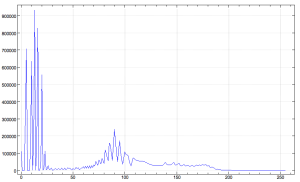
Now in my case the plot is suspiciously wiggly. For a range of values the plot swings up and down wildly, as if the scanner (the original source) has some sort of quantisation artefact. For example, as it might appear if the bottom two bits were mysteriously returned as 0 1 most of the time.
I can recover some accuracy in the bottom 2 bits by rescaling the image. Since this requires me to actually remember some things from my degree I’ll do that later.
Appendix A – String to Number
Convert string to number:
atoi =: [:(+10&*)/ [:|.'0123456789'&i. atoi '3155' 3155 1+ atoi '3155' NB. add one to prove that it's a number 3156
New things: «|.» is reverse, and dyadic «x i. y» is the index of y within x.
atoi uses cap, «[:», twice for the same reason: the trident «([: g h) y» is equivalent to «g h y» (we can’t use a bident because «(g h) y» is not «g h y», it’s «g y h y»). This is simple composition and can also be achieved with the «@» conjunction; «u@v y» is «u v y». Unfortunately conjunctions associate left-to-right (in so far as this is a reasonable way to think about it), so that «u @ v @ w» is «(u@v)@w». That means many more brackets in the form that uses «@»:
(+10&*)/@(|.@('0123456789'&i.))
The ability of cap to reduce parens is mentioned in its documentation.
So now we can glue everything together.
pgmxym t +----+----+---+ |3301|3397|255| +----+----+---+
That’s a vector of boxes, each box containing a character array (string). Boxes are one of the atomic types that can appear as the 0-cells of an array. They’re just like pointers. They’re useful in this case because the answers, which are strings, are different lengths. We can’t have an array with rows of different length, so we can’t form an array directly from the strings ‘3301’, ‘3397’, ‘255’, because they’re not all the same length. So they’re boxed.
We can unbox with «>»:
> pgmxym t 3301 3397 255
and then convert to a number:
atoi > pgmxym t 332 335 95 180
Oh dear. We can see by comparing with the previous output that something has gone wrong with the rank of atoi. We could fix the rank with: «atoi”1 > pgmxyd t» but this still gives the wrong answers: 3301 3397 2560. The last result is wrong because atoi wasn’t applied to the string ‘256’ it was applied to the string ‘256 ‘ because when «>» produced its results they were an array so all the rows had to be the same length. Evidently atoi doesn’t work when there are non-digits in the string. The solution I chose was to compose atoi with «>»:
atoi @ > pgmxyd t 3301 3397 255
Yay!